Projects
Our highly collaborative and interdisciplinary projects are the key packages of work at the Franklin. Through these projects we create momentum to tackle the big questions and challenges.

Experimental Automation

Defining how coronaviruses enter and traffic in cells

Citizen Science
Molecular Organisation of Cell Interfaces
Liquid Phase Electron Microscopy and Spectroscopy

Structural Elucidation
Structural Neurobiology
In Utero
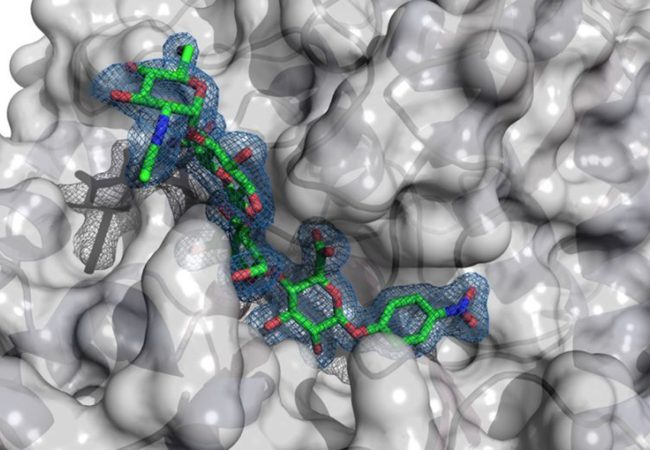
Structural Glycobiology

Electron Detector Development

Electron Diffraction

Cryo-ptycho-tomography
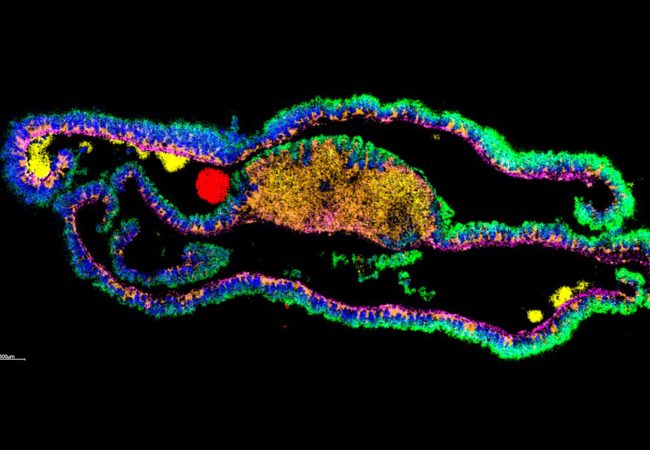
Subcellular Imaging

Biochemical Microscopy for imaging across Molecular Scales

Digital Twin Cell

3D Protein Atlas of Brain

Disease X

Chromatic Correction